
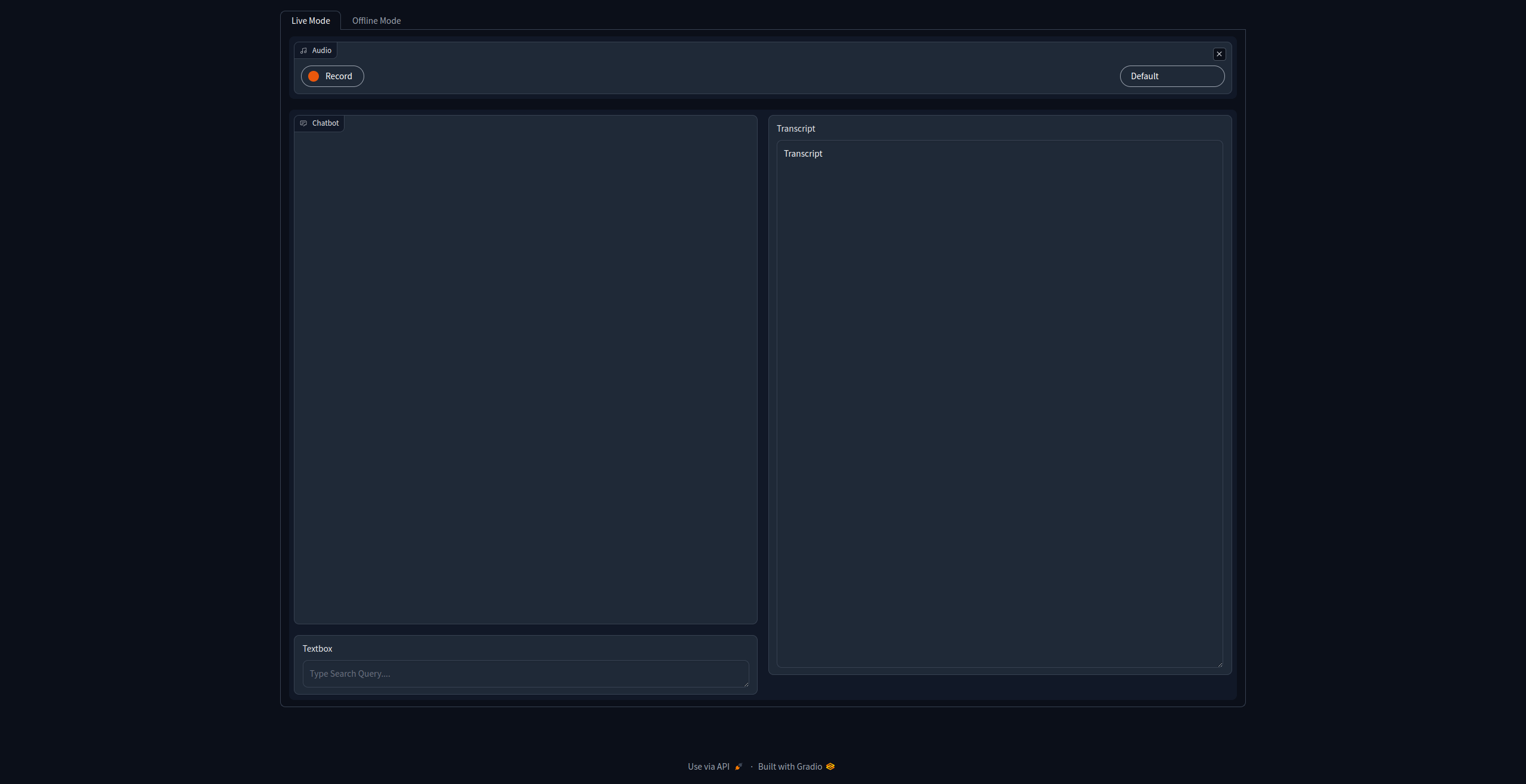
Live + Offline Automatic Speech Recognition
To transcribe meetings live and provide search for the meeting transcriptions. With efficient processing
The Problem
I faced the task of enabling search within meeting transcripts, spanning discussions among 2 to 4 participants, whether conducted online or offline. The aim was to seamlessly reference past discussions during live conversations within the same group.

Solution
The objective was to develop a foundational solution that could later evolve to address this challenge comprehensively. It served as a checkpoint to identify all essential considerations for tackling the aforementioned problem, including:
- Real-time transcription of live conversations, regardless of their online or offline nature.
- Retrieval of past meeting conversations within the same group.
- Ensuring the accuracy and efficiency of reference searches.
- Exploring various scenarios to be accounted for in the solution design process.

Tech Stack
- Vector DB - Qdrant - A Rust made mature vector only database which is opensource
- Transcription Model - Whisper, opensource and one of the top transcription models
- Text to Text Transformer Model - Google T5 Model
- User Interface - Gradio - Apart from it being best known for AI software interfaces, its also best when using its api client
Functional Features
- Vector Search provided does both semantic and keyword based context retrieval
- Provides Real-time transcription of live conversations, also provides offline transcription
- Accuracy and efficiency of reference Searches
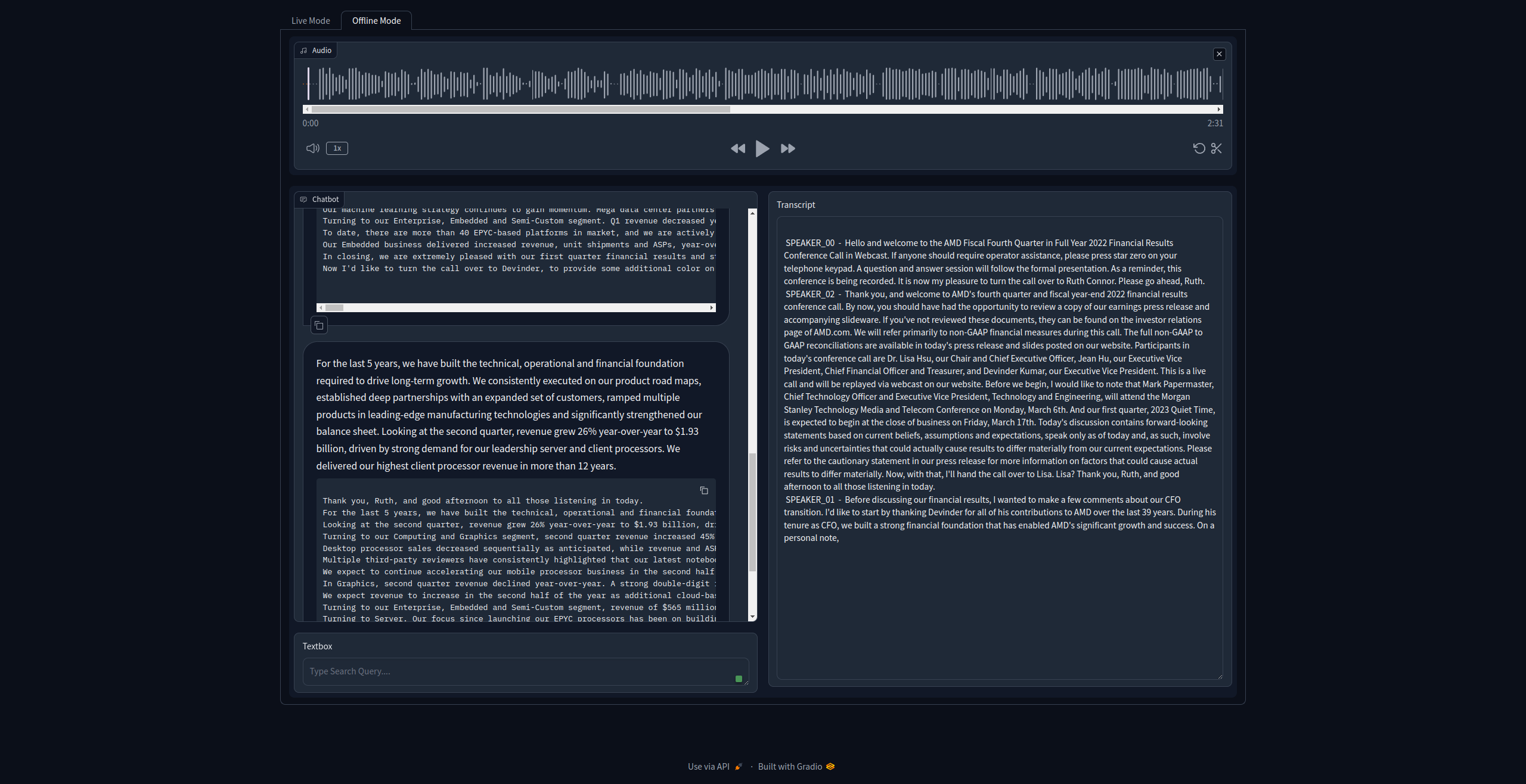
Non-Functional Features
- Semantic and summation of long context
- Project is Enterprise grade from ci/cd automation, infra as code, scalablity and very coosen stack
- Hybrid vector search - Dense and Sparse
- Realtime and efficient on resources
- Real time live recording works at 6GB GPU memory and rest models work on CPU inference
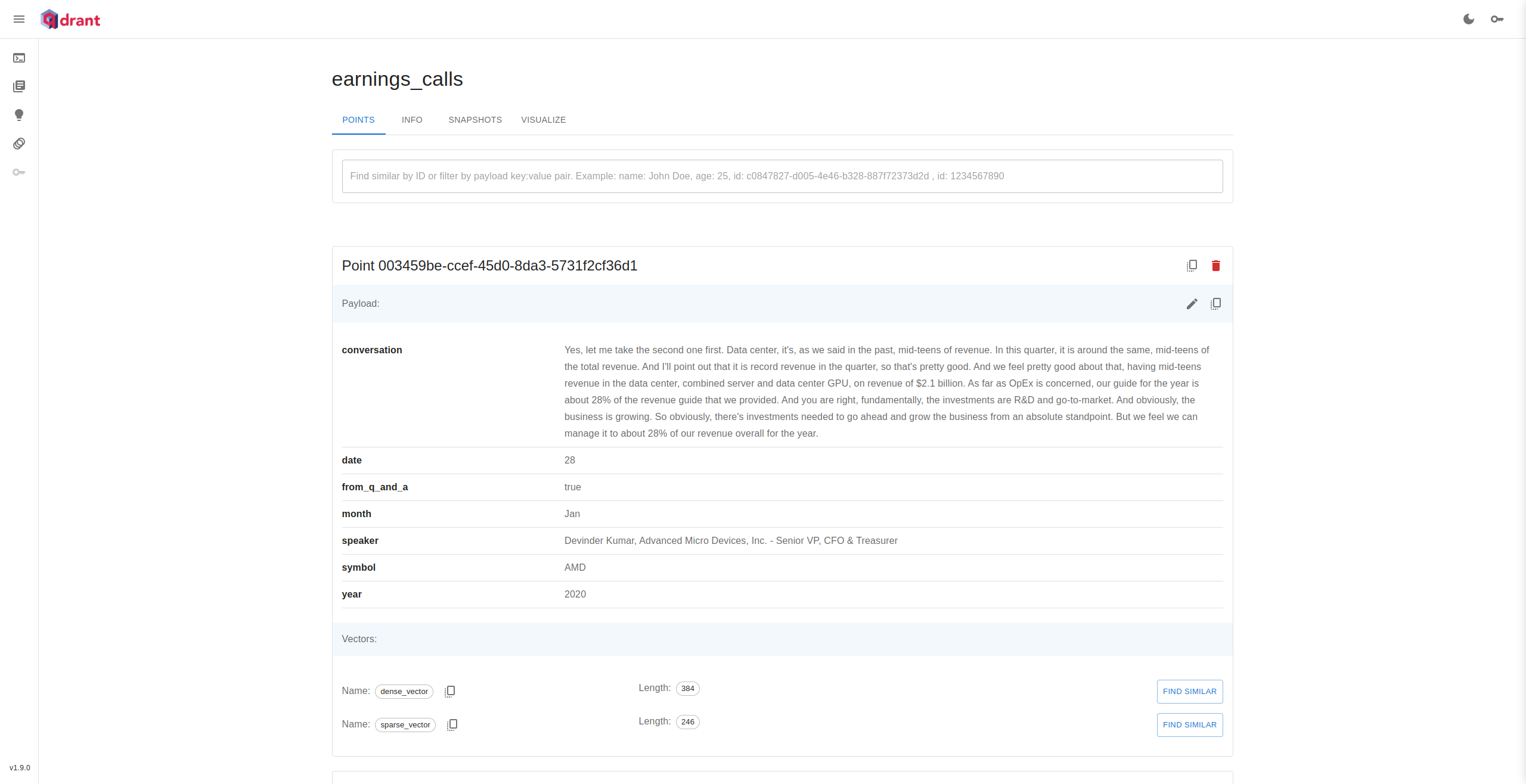
Project Outcome
Achieved the actual poc to be done on live meeting transcription and learnt details accross different models including diarization (speaker recognition) and other problems which occur during live stream transcription. Also issues like very long context which is not supported by current models with summarization as well as context switching